


 我要发帖
我要发帖


近日谷歌公司宣布推出 Gemini Embedding,是一款基于 AI 的文本处理模型,现已集成至 Gemini API,标志着谷歌在AI技术应用上的又一里程碑,该模型在 Massive Text Embedding Benchmark(MTEB)中拔得头筹,超越了 Mistral、Cohere 和 Qwen 等竞争对手,成为当前性能最强的文本嵌入模型。

什么是文本嵌入模型?
简单来说,文本嵌入模型就像是一位精通语言 “翻译” 的大师,它能够将人类使用的文本语言,转换成计算机能够轻松理解的数值表示,也就是向量。通过这种转换,计算机就可以对文本进行语义搜索、推荐系统构建、文档检索等一系列操作,大大提升了对文本数据处理和分析的效率与准确性。
Gemini Embedding实力数据
Gemini Embedding 将文本转换为数值表示(向量),从而支持语义搜索、推荐系统和文档检索等功能。它在 MTEB 基准测试中表现出色,平均任务得分为 68.32,显著高于 Linq-Embed-Mistral 和 gte-Qwen2-7B-instruct 等模型,达到 State-of-the-art。
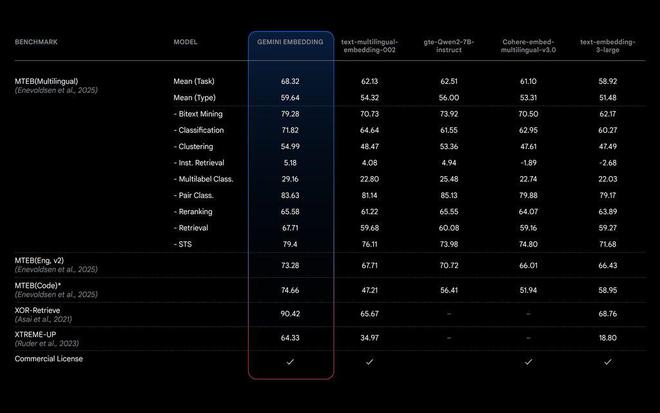
从具体得分来看,它在配对分类上斩获 85.13 的高分,在检索方面得分 67.71,重排序得分 65.58。这些亮眼的数据直接表明,Gemini Embedding 在诸如 AI 搜索引擎优化、文档分析以及聊天机器人优化等实际应用场景中,具备显著优势。它能够更加精准地理解文本之间的语义关系,从而为用户提供更贴合需求的服务。
Gemini Embedding强大特点
- 性能卓越:在 MTEB 多语言排行榜上,Gemini Embedding 以平均得分 68.32 分的绝对优势,领先第二名 5.81 分,而且它支持多种任务类型,无论是复杂的检索任务,还是精细的分类任务,都能出色完成。
- 语义理解能力强:Gemini Embedding 继承了 Gemini 大模型强大的语言理解能力。它无需额外调整,就能轻松适应不同领域的文本理解需求,无论是专业术语堆积的金融领域,还是条文严谨的法律领域,亦或是知识体系庞大的医学领域,它都能精准把握文本含义,为后续的分析和处理提供坚实基础。
- 输入输出能力大幅提升:它的输入长度支持 8K 个 tokens,相比以往模型,能够处理更长篇幅的文章,不会因文本过长而 “力不从心”。输出向量维度更是达到 3K,是之前模型的 4 倍,使得语义表达更加精确。同时,它还支持 MRL 技术,可以根据实际需要灵活调整向量维度(3K、2K、1K 或 512),在保证语义表达的同时,节省存储空间,实现了性能与资源利用的完美平衡。
- 多语言支持超强:Gemini Embedding 支持 100 多种语言,这一数量远超以往模型。即使面对专门为某种语言设计的模型,它在多语言处理方面的表现依然更胜一筹。无论是跨语言的文本检索,还是多语言的内容分类,它都能轻松应对,为全球化的应用提供了有力支持。
Gemini Embedding应用场景
- 搜索引擎优化:Gemini Embedding 的出现,将彻底改变传统搜索引擎的模式。它能够极大地提升搜索结果的相关性,支持谷歌正在测试的纯 AI 驱动搜索模式。当用户输入一个模糊的问题时,它不再仅仅依赖关键词匹配,而是深入理解用户意图,综合多方面信息,给出更精准、更个性化的搜索结果,让用户在海量信息中快速找到所需。
- 多语言应用:在全球化交流日益频繁的今天,Gemini Embedding 的多语言支持能力大有用武之地。它可以增强跨语言翻译的准确性,让不同语言的人们交流更加顺畅;提升客户服务自动化水平,实现多语言客户咨询的精准回应;优化内容排名,使不同语言的优质内容都能得到应有的展示机会。
- 企业服务:对于企业而言,Gemini Embedding 可以优化基于 Google Cloud 的 AI 分析,帮助企业从海量数据中挖掘出更有价值的信息;提升语义搜索效率,让企业员工能快速找到所需文档和资料;实现自动化数据检索,大大提高企业运营效率,在激烈的市场竞争中脱颖而出。










 暂无评论
暂无评论
 关于作者
关于作者 热榜
热榜

 关注石油同学
关注石油同学  扫码进入移动端
扫码进入移动端 